Gloss Representation
- Gloss는 수어(수화 언어)의 단어(또는 기호)를 문자 언어로 나타낸 것입니다. 예를 들어, 영어 수어(ASL)에서 "사랑"이라는 단어는 "LOVE"라는 영어 단어로 글로스할 수 있습니다.
- Gloss는 수어를 문자 언어로 변환하여 연구자나 학습자가 이해하기 쉽게 만드는 데 사용됩니다. 그러나 이는 완전한 번역이 아니며, 주로 단어 수준에서 의미를 전달하는 데 중점을 둡니다.
Mid-Level Sign Gloss Representation
- Mid-level sign gloss representation은 수어를 분석하거나 처리할 때 사용하는 중간 수준의 표현 방법입니다. 이는 원래의 수어 영상 또는 수어의 고유한 특성과 완전히 문자화된 표현 사이의 중간 단계로 볼 수 있습니다.
- 이 표현은 수어의 문법적, 의미적 요소를 더 잘 반영할 수 있도록 설계되었습니다. 예를 들어, 수어에는 손 모양, 위치, 움직임, 얼굴 표정 등이 중요한데, mid-level gloss는 이러한 요소들을 더 잘 포착할 수 있습니다.
- 이는 수어 인식 시스템, 기계 번역 시스템, 수어 교육 등 다양한 응용 분야에서 중요한 역할을 합니다. mid-level gloss는 수어의 복잡한 요소들을 더 세밀하게 표현하여 시스템이 이를 더 정확하게 이해하고 처리할 수 있도록 합니다.
ex)
LOVE:
- Handshape: "A-hand"
- Location: "chest"
- Movement: "double tap"
- Non-manual markers: "neutral facial expression"
GLOSS: "HELLO"
- Handshape: "B-hand"
- Location: "forehead"
- Movement: "outward flick"
- Non-manual markers: "smile"
Ground-Truth Timing Information의 정의
- Ground-Truth: 이는 데이터에 대한 "참된" 또는 "정확한" 정보를 의미합니다. 보통 수동으로 라벨링된 데이터로서, 실제 관찰된 현상이나 상황을 반영합니다.
- Timing Information: 이는 이벤트나 행동이 발생한 시간 정보를 의미합니다.
따라서 ground-truth timing information은 어떤 이벤트나 행동이 정확히 언제 발생했는지를 나타내는 정확한 시간 정보를 의미합니다. 예를 들어, 비디오에서 특정 행동(예: 문 열기)이 발생한 정확한 프레임이나 음성 녹음에서 특정 단어가 발화된 정확한 시간 정보를 포함합니다.
ex)
- 음성 인식:
- 음성 데이터에서 각 단어나 음소가 발화된 정확한 시간 정보. 예를 들어, "hello"라는 단어가 1.2초에서 1.6초 사이에 발화되었다는 정보.
- 비디오 분석:
- 비디오 데이터에서 특정 행동(예: 사람의 걸음걸이)이 발생한 정확한 프레임. 예를 들어, 15초에 사람이 문을 열기 시작하고 17초에 문을 완전히 연다는 정보.
- 수어 인식:
- 수어 비디오에서 각 수어 기호(sign)가 시작하고 끝나는 시간 정보. 예를 들어, "사랑"이라는 수어가 2.3초에서 2.8초 사이에 수행되었다는 정보.
Abstract
수어 번역 시스템이 효과적으로 작동하기 위해 수어의 각 기호를 글로스로 변환하여 처리하는 과정이 필요하다
1. Introduction
목표는 written language → video of sign 또는 video of performing continuous sign(연속 수어 비디오) → spoken language
연구는 완전한 구어 번역보다는 수어 글로스의 시퀀스를 인식하는 데 중점을 두고 있음.
그래서 수어 번역 작업은 spatio-temporal machine translation task이다.
- spatio-temporal
- 공간적 요소 (Spatial Elements):
- 손의 위치
- 손의 모양
- 손의 방향 및 경로
- 시간적 요소 (Temporal Elements):
- 각 수어 기호의 시작 및 종료 시점
- 손 움직임의 순서
이러한 요소들을 모두 고려하여 수어를 텍스트나 다른 언어로 번역하는 것이 spatio-temporal machine translation task의 핵심
Sign Segmentation - 1. Topic-comment 구조로 이루어진 수어 문장을 인식해야함.
-Topic-comment 구조
개념 설명
- Topic (주제):
- 문장의 주제는 무엇에 대해 말하고 있는지를 나타냅니다. 이는 문장의 중심이 되는 개념이나 객체입니다.
- 주제는 보통 문장 초반에 등장하여 독자나 청자에게 문장이 무엇에 대해 이야기할 것인지를 알려줍니다.
- Comment (설명):
- 설명은 주제에 대해 무엇을 말하고 있는지를 나타냅니다. 이는 주제에 대한 정보, 설명, 동작 등을 포함합니다.
- 설명은 주제에 대한 구체적인 내용을 제공합니다.
예시
- 한국어:
- "그 책은 재미있다."
- Topic: "그 책은"
- Comment: "재미있다."
- "그 책은 재미있다."
- 영어:
- "As for that book, it is interesting."
- Topic: "As for that book"
- Comment: "it is interesting."
- "As for that book, it is interesting."
- 수어 (ASL: American Sign Language):
- "책, 재미있다."
- Topic: "책" (Book)
- Comment: "재미있다" (Interesting)
- "책, 재미있다."
반면 음성 기반 인식 및 번역 시스템이 음성 데이터를 처리할 때, 음소(언어의 최소 소리 단위) 간의 일시적 멈춤을 이용하여 발화된 문장을 분할한다
예시
- 음성 데이터 입력:
- "I am going to the store"라는 문장이 음성으로 입력됩니다.
- 음소 간 일시적 멈춤 탐지:
- 시스템은 각 음소 사이의 짧은 멈춤을 탐지합니다.
- 예를 들어, /aɪ/ (I)와 /æm/ (am) 사이에 멈춤이 있을 수 있습니다.
- 분할 및 인식:
- 멈춤을 기반으로 음성을 분할하여 각 음소를 인식합니다.
- 이를 통해 "I", "am", "going", "to", "the", "store"라는 단어들로 분할됩니다.
- 번역 및 처리:
- 인식된 단어들을 번역하거나 다른 형태로 처리합니다.
Sign Language Recognition and Understanding
<시스템 요구 사항>
- 고차원 공간-시간 데이터: 수어 비디오는 고차원적이고 시간에 따라 변하는 데이터이므로, 모델은 이러한 복잡한 데이터를 처리할 수 있어야 합니다.
- 3D 수어 공간: 수어는 3D 공간에서 이루어지므로, 모델은 수어 사용자의 손 움직임, 위치, 모양 등을 3차원적으로 이해해야 합니다.
- 결합적 이해: 모델은 개별적인 손 움직임뿐만 아니라, 이러한 요소들이 어떻게 결합되어 의미를 전달하는지도 이해해야 합니다.
<문제의 복잡성>
- 비동기 다중 조음: 수어는 동시에 여러 움직임과 표정을 사용하므로, 이러한 비동기적이고 복합적인 특성을 모델이 처리하기 어려운 점이 있습니다.
<현재의 한계>
- 제한된 영역: 현재 최첨단 기술은 수어 글로스를 인식할 수 있지만, 주로 특정한 담화 영역(예: 날씨 예보)에서만 유효합니다.
- 글로스 인식: 모델이 수어 문장 전체를 이해하기보다는 개별 글로스를 인식하는 데 중점을 두고 있습니다.
Sign Language Translation
PHOENIX14T 데이터셋
- PHOENIX14T: Camgoz et al.이 발표한 이 데이터셋은 수어 비디오에서 구어로 번역할 수 있는 최초의 공개 데이터셋입니다.
- 중요성: 이 데이터셋은 연구자들이 수어 비디오에서 구어 번역 모델을 훈련시키고 평가하는 데 중요한 자원을 제공합니다.
신경 기계 번역(NMT) 접근
- NMT 접근법: 저자들은 수어 번역을 신경 기계 번역 문제로 접근하여, 주의 메커니즘 기반의 NMT 모델을 사용했습니다.
- 주의 메커니즘: 주의 메커니즘은 번역 과정에서 중요한 부분에 집중할 수 있게 도와주는 기술로, NMT 모델의 성능을 향상시키는 데 중요한 역할을 합니다.
Sign2Text 모델
- Sign2Text: 이 모델은 비디오 기반의 수어 번역에서 최초로 끝에서 끝까지의(End-to-End) 수어 비디오에서 구어 문장으로 번역하는 모델입니다.
- 실현된 작업: 여러 SLT 작업을 정의하고 이를 통해 수어 비디오에서 구어 문장으로 직접 번역하는 과정을 구현했습니다.
주요 발견
- 글로스 기반 중간 수준 표현: 수어 인식에서 글로스를 중간 단계로 사용하는 것이 SLT 성능을 향상시키는 데 중요한 역할을 했다는 점을 발견했습니다.
- 성능 향상: 끝에서 끝까지의 Sign2Text 접근 방식보다 훨씬 더 나은 성능을 보였습니다.
Sign2Gloss2Text 모델
- Sign2Gloss2Text 모델: 이 모델은 두 단계로 구성됩니다.
- 글로스 인식: 연속 수어 비디오에서 글로스를 인식하는 단계. 최첨단 CSLR 방법을 사용하여 이 작업을 수행합니다. 이 단계는 비디오를 개별적인 글로스 단위로 토큰화하는 역할을 합니다.
- 텍스트 간 변환: 인식된 글로스를 주의 메커니즘 기반의 NMT 네트워크에 전달하여 최종적으로 구어 문장을 생성합니다.
¿ Sign2Gloss2Text가 Sign2Text보다 성능이 좋은 이유¿
1. 수어 글로스의 수는 그것들이 나타내는 비디오 프레임의 수보다 훨씬 적다 ⇒ 장기 의존성 문제도 피할 수 있음.
수어 글로스와 비디오 프레임 수 비교
- 글로스의 수: 수어 비디오에서 인식되는 글로스의 수는 일반적으로 그 비디오의 전체 프레임 수보다 적습니다.
- 비디오 프레임 수: 비디오 프레임은 연속적인 이미지를 구성하는 개별 단위로, 수어 비디오에서는 매우 많은 프레임이 포함됩니다.
글로스 표현의 장점
- 공간적 임베딩 대신 글로스 표현: 비디오 프레임에서 추출한 공간적 임베딩을 사용하는 대신, 글로스 표현을 사용함으로써 모델의 복잡성을 줄이고 효율성을 높일 수 있습니다.
- 장기 의존성 문제 회피: 글로스 표현을 사용하면, 긴 비디오 시퀀스에서 발생하는 장기 의존성 문제를 피할 수 있습니다. 이는 Sign2Text 모델이 비디오의 모든 프레임을 처리하는 동안 발생할 수 있는 문제를 해결하는 데 도움이 됩니다.
2. Sign2Text 훈련에서 수어 문장을 이해하기 위한 직접적인 지도가 부족하다.
주요 문제점
- 직접적인 지도 부족: Sign2Text 모델이 훈련될 때 수어 문장을 이해하기 위한 명확한 중간 감독이 부족하다는 것이 주요 문제점으로 지적됩니다.
- 작업의 복잡성: 수어 번역 작업의 복잡성을 고려할 때, 중간 감독 없이 수어를 이해하는 것은 매우 어려운 일입니다.
제안된 접근 방식
- 수어 트랜스포머 접근 방식: 이 논문에서는 새로운 수어 트랜스포머 접근 방식을 제안하여 이러한 문제를 해결하고자 합니다.
- 두 단계 파이프라인의 회피: 번역이 인식 정확도에만 의존하는 두 단계 파이프라인을 피하고, 더 효율적이고 직접적인 학습 방법을 제안합니다.
새로운 학습 방법
- 공동 학습: 수어 비디오의 공간적 표현을 통해 수어 인식과 번역을 공동으로 학습합니다. 이는 수어 비디오의 시각적 데이터를 사용하여 수어 인식과 번역 작업을 동시에 수행하는 것을 의미합니다.
- 끝에서 끝까지 학습: 이 방법은 입력부터 출력까지 모든 단계를 하나의 통합된 모델로 학습하는 끝에서 끝까지의 학습 방식을 사용합니다.
2. Related Work
기존 CSLR방법의 문제 : 수어 문장과 대응하는 구어 문장의 순서가 다름. 또 기존 방법들은 수어 비디오와 주석이 동일한 시간 순서를 따른다는 가정을 기반으로 함.
해결 : Camgoz et al.은 PHOENIX14T 데이터셋을 발표하고, CNN과 attention 메커니즘 기반의 NMT 방법을 결합하여 end-to-end SLT 모델을 구현함.
그 후 Ko et al.은 유사한 접근 방식을 사용하여, 몸의 키포인트 좌표를 입력으로 사용하고 한국 수어 데이터셋에서 그 성능을 평가함.
이 연구에서는 여러 상호 의존적인 트랜스포머 네트워크를 동시에 훈련하여 관련된 과제를 공동으로 해결하는 새로운 아키텍처를 제안한다. 그런 다음 이 아키텍처를 동시에 인식 및 번역하는 문제에 적용하여 공동 훈련이 상당한 이점을 제공한다는 것을 보여준다.
3. Sign Language Transformers
목표 : 주어진 수어 비디오 V=(I1,...,IT)에 대해 N개의 글로스로 이루어진 수어 글로스 시퀀스
G=(g1,...,gN)와 U개의 단어로 이루어진 구어 문장 S=(w1,...,wU)를 생성하는 조건부 확률
p(G∣V)와 p(S∣V)를 학습하는 것
이러한 조건부 확률을 모델링하는 것은 시퀀스-투-시퀀스 작업이며, 여러 가지 도전 과제를 제시한다. 두 경우 모두, 소스 도메인의 토큰 수가 대응하는 타겟 시퀀스 길이보다 훨씬 크다.
(T>>N 및 T>>U)
또 수어 비디오 (V)와 구어 문장(S)은 어휘와 문법 규칙, 순서가 다르기 때문에 V와 S간의 매핑은 non-monotonic.
이전의 시퀀스-투-시퀀스 기반 SLT 연구는 두 그룹으로 나눌 수 있다:
첫 번째 그룹: 이중 단계 접근법
첫 번째 그룹은 문제를 두 단계로 나눕니다. 이들은 CSLR을 초기 과정으로 간주한 후, 텍스트-투-텍스트 번역 작업으로 문제를 해결하려고 시도합니다. Camgoz et al.은 최첨단 CSLR 방법을 사용하여 수어 글로스를 얻고, 주의 메커니즘 기반의 텍스트-투-텍스트 NMT 모델을 사용하여 수어 글로스에서 구어 문장 번역을 학습했습니다(예: p(S∣G)). 그러나 이 접근 방식은 중간 수준의 글로스 표현에서 정보 병목 현상을 초래합니다. 이는 네트워크가 학습한 수어 글로스 주석의 품질에 따라 번역 모델의 성능이 제한되며, 수어 글로스는 원래 수어 비디오에 있는 중요한 세부 사항과 정보를 무시하는 불완전한 주석이기 때문입니다.
두 번째 그룹: 직접 번역 접근법
두 번째 그룹의 방법은 중간 표현 없이 수어 비디오 표현에서 구어로 번역하는 데 중점을 둡니다. 이러한 접근 방식은 p(S∣V)를 직접 학습하려고 시도합니다. 충분한 데이터와 고도로 정교한 네트워크 아키텍처가 주어진다면, 이러한 모델은 이론적으로 인간이 해석 가능한 정보를 필요로 하지 않는 끝에서 끝까지의 SLT를 실현할 수 있습니다. 그러나 수어 이해를 직접적으로 지도하는 감독이 부족하기 때문에 이러한 방법은 현재 사용 가능한 데이터셋에서 성능이 상당히 낮습니다.
제안된 접근 방식
:p(G∣V)와 p(S∣V)를 끝에서 끝까지 공동으로 학습할 것을 제안
훈련 과정에서, Sign Language Recognition Transformer (SLRT) 인코더에 CTC 손실 형태의 중간 글로스 감독을 주입하여 네트워크가 더 의미 있는 시공간적 수어 표현을 학습하도록 돕는다. 디코더로는 한 번에 한 단어씩 예측하여 구어 문장 번역을 생성하는 자가 회귀 Sign Language Translation Transformer (SLTT)를 사용
3.1 Spatial and Word Embeddings
소스 및 타겟 토큰인 수어 비디오 프레임과 구어 단어를 임베딩하는 것으로 시작
단어 임베딩의 경우, 훈련 중 처음부터 초기화된 선형 레이어를 사용하여 단어의 원-핫 벡터 표현을 더 밀집된 공간으로 투사
비디오 프레임을 임베딩하기 위해서는 SpatialEmbedding 접근 방식을 사용하며, 각 이미지를 CNN을 통해 전파

여기서 mu는 구어 단어 wu의 임베딩 표현을 나타내고, ft는 CNN에서 얻은 비선형 프레임 레벨 공간 표현을 나타냄.

다른 시퀀스-투-시퀀스 모델들과 달리, 트랜스포머 네트워크는 시퀀스 내에서 위치 정보를 가지지 않는다 ⇒ Positional Encoding
3.2 Sign Language Recognition Transformers
SLRT (Sign Language Recognition Transformer) 설명
SLRT의 목표는 연속 수어 비디오에서 글로스를 인식하면서 의미 있는 시공간 표현을 학습하여 최종적으로 수어 번역을 수행하는 것
위치 인코딩된 공간 임베딩 f^1:T\hat{f}_{1:T}를 사용하여 트랜스포머 인코더 모델을 훈련합니다. SLRT의 입력은 먼저 셀프 어텐션(Self-Attention) 레이어에 의해 모델링되며, 이는 비디오 프레임 표현 간의 문맥적 관계를 학습합니다. 셀프 어텐션의 출력은 비선형 포인트-와이즈 피드 포워드 레이어를 통해 전달됩니다. 모든 작업은 잔차 연결(residual connections)과 정규화(normalization)를 따라 수행되어 훈련을 돕습니다. 이 인코딩 과정을 다음과 같이 수식화합니다:

여기서 zt는 시공간 표현을 나타내며, 이는 시간 단계 t에서 SLRT가 생성한 프레임 It의 시공간 표현입니다.
중간 감독 (Intermediate Supervision)
중간 감독을 도입하여 네트워크가 수어를 이해하고 의미 있는 수어 표현을 학습하도록 유도합니다. SLRT는 p(G∣V)를 모델링하고 수어 글로스를 예측하도록 훈련됩니다. 수어의 시공간적 특성 때문에 글로스는 비디오 프레임과 일대다 관계를 가지지만 동일한 순서를 공유합니다.
CTC 손실 사용
프레임 수준의 주석을 사용하여 SLRT를 교차 엔트로피 손실로 훈련할 수 있지만, 그러한 정밀한 글로스 주석은 드뭅니다. 대신 약한 감독의 한 형태로 시퀀스-투-시퀀스 학습 손실 함수인 CTC를 사용합니다.
시공간 표현 z1:Tz_{1:T}을 주어진 상태에서, 선형 프로젝션 레이어와 소프트맥스 활성화를 통해 프레임 수준 글로스 확률 p(gt∣V)를 얻습니다. 그런 다음 가능한 모든 V에서 G로의 정렬을 마지널라이즈하여 CTC를 사용하여 p(G∣V)를 계산합니다:

여기서 π는 경로를 나타내고 B는 G에 해당하는 모든 유효한 경로의 집합입니다. 그런 다음 p(G∣V)를 사용하여 CSLR 손실을 다음과 같이 계산합니다:
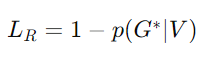
여기서 G∗는 실제 글로스 시퀀스(ground truth gloss sequence)를 나타냅니다.
3.3 Sign Language Translation Transformers
SLTT (Sign Language Translation Transformer) 설명
- 구어 문장 임베딩:
- 목표 구어 문장 S를 특수 토큰 <bos>로 시작
- 위치 인코딩된 단어 임베딩을 추출
- masked self-attention:
- 위치 인코딩된 단어 임베딩을 masked self-attention layer에 전달.
- 각 토큰이 이전 토큰만 사용할 수 있도록 마스크를 적용.
- 인코더-디코더 어텐션 모듈:
- SLRT와 SLTT 셀프 어텐션 레이어에서 추출된 표현을 결합하여 인코더-디코더 어텐션 모듈에 전달.
- 소스 시퀀스와 타겟 시퀀스 간의 매핑을 학습.
- 출력은 non-linear point-wise feed forward layer를 통과.
- 잔차 연결 및 정규화:
- 모든 작업 후 잔차 연결과 정규화를 수행하여 훈련을 도움.
4. Dataset and Translation Protocols
PHOENIX14T 데이터셋을 가지고 평가함.
1. Sign2Text
- 목표: 연속 수어 비디오에서 글로스와 같은 중간 표현을 거치지 않고 직접 구어 문장으로 번역하는 것.
- 특징: 중간 표현 없이 수어 비디오에서 구어 문장으로 직접 번역하기 때문에 이상적으로는 가장 높은 성능을 기대할 수 있지만 이는 매우 정교한 네트워크 아키텍처와 데이터를 필요로 하며, 현재의 기술로는 달성하기 어렵다.
2. Gloss2Text
- 목표: 실제 글로스 시퀀스를 독일어 구어 문장으로 번역하는 텍스트-투-텍스트 번역 문제.
- 특징: 이 접근 방식은 글로스 주석을 완벽한 수어 인식으로 가정하여 수행됨. 그러나 글로스는 다채널 시계열 신호의 텍스트 표현이므로 정보 병목 현상을 초래할 수 있다. 따라서, 이상적인 상황에서는 Sign2Text 시스템이 Gloss2Text 시스템보다 더 우수해야 함.
3. Sign2Gloss2Text
- 현재 최첨단: 이 접근 방식은 연속 수어 비디오에서 글로스 시퀀스를 추출하기 위해 CSLR 모델을 사용하고, 그런 다음 이 글로스를 텍스트-투-텍스트 번역 문제로 처리하여 구어 문장을 생성함.
- 과정: 먼저 수어 비디오에서 글로스를 추출한 후, 추출된 글로스를 텍스트-투-텍스트 번역 네트워크를 통해 구어 문장으로 변환.
4. Sign2Gloss→Gloss2Text
- 유사 접근 방식: Sign2Gloss2Text와 비슷하게 CSLR 모델을 사용하여 글로스 시퀀스를 추출.
- 특징: 이 접근 방식은 텍스트-투-텍스트 번역 네트워크를 처음부터 훈련하는 대신, 실제 글로스 주석으로 훈련된 최상의 Gloss2Text 네트워크를 사용하여 구어 문장을 생성.
새로운 프로토콜 소개
1. Sign2Gloss
- 정의: 기본적으로 연속 수어 인식(CSLR)을 수행하는 프로토콜.
- 목표: 수어 비디오에서 글로스 시퀀스를 추출하는 작업에 초점을 맞춤.
2. Sign2(Gloss+Text)
- 정의: 연속 수어 인식과 번역을 공동으로 학습하는 프로토콜.
- 목표: 수어 비디오에서 글로스와 구어 문장을 동시에 예측하는 작업을 수행. 이는 연속 수어 인식과 번역이 서로 보완할 수 있는 학습을 가능하게 함.
5. Quantitative Results
수어 인식 및 번역 모델의 실험 설정과 그 결과
최적의 Sign2Gloss 구성을 바탕으로 Sign2Text 및 Sign2(Gloss+Text) 모델을 학습하고, 다양한 인식 손실 가중치가 성능에 미치는 영향을 조사
5.1 Implementation and Evaluation Details
Framework: JoeyNMT의 수정된 버전 사용. 네트워크의 모든 구성 요소는 PyTorch프레임워크를 사용하여 구축되었고 CTC빔 검색 디코딩의 경우 TensorFlow구현을 활용
Network Details: 각 레이어에 512개의 히든 유닛과 8개의 헤드를 사용한 트랜스포머. 모든 네트워크는 Xavier초기화를 사용해 처음부터 훈련. 과적합 방지를 위해 트랜스포머 레이어와 단어 임베딩에 드롭아웃 적용. 드롭아웃 비율은 0.1
Performance Metrics: 연속 수어 인식(CSLR)성능을 평가하기 위해 Word Error Rate(WER)사용.
Training: Adam옵티마이저 사용, 배치크기는 32, 학습률을 10^-3, weight decay는 10^-3.
plateau학습률 스케줄링을 사용하여 개발 세트의 성능을 추적. 네트워크는 100번의 반복마다 평가되고 개발 점수가 8번의 평가 단계동안 감소하지 않으면 학습률을 0.7배 줄임. 이 과정은 학습률이 10^-6이하로 떨어질때까지 반복.
Decoding: 훈련 및 검증 단계에서 그리디 검색을 사용해 글로스 시퀀스와 구어 문장을 디코딩.
추론 시에는 0~10의 빔 폭을 사용하여 빔 검색 디코딩.
알파 값이 0~2범위인 길이 페널티 구현. -> 가장 성능이 좋은 빔 폭과 알파의 조합을 찾아 테스트 세트 평가에 사용.
5.2 Text-to-Text Sign Language Translation
트랜스포머를 텍스트-투-텍스트 수어 번역에 활용한 결과, 모든 작업에서 성능이 향상됨.
개발 세트에서 25.35, 테스트 세트에서 24.54의 BLEU-4점수를 기록.
5.3 Sign2Gloss
실험 세트 1: CNN 아키텍처 선택
- 사용한 CNN 아키텍처:
- EfficientNet (B0, B4, B7): ImageNet에서 훈련된 최신 아키텍처.
- Inception: CNN+LSTM+HMM 구성에서 수어 인식을 위해 사전 훈련된 네트워크.
- 실험 설정:
- 두 레이어의 트랜스포머 인코더 모델 사용.
- 결과:
- 더 고급 공간 임베딩 레이어(B0와 B7 비교)를 사용할수록 인식 성능이 향상됨.
- 사전 훈련된 특징을 사용할 때 네트워크가 더 많은 이점을 얻음. 이는 사전 훈련된 네트워크가 수어 비디오를 이미 본 경험이 있어 더 의미 있는 표현을 잠재 공간에 임베딩할 수 있는 커널을 학습했기 때문임.
- 배치 정규화(Batch Normalization)와 ReLU를 사용하여 입력을 정규화하고 비선형 표현을 더 추상적으로 학습할 수 있도록 함. 이로 인해 개발 세트와 테스트 세트에서 각각 7% 및 6%의 절대 WER 감소를 달성함.
- 최적의 설정:
- ReLU 다음에 배치 정규화를 적용한 [39]의 사전 훈련된 CNN 특징을 사용.
실험 세트 2: 트랜스포머 레이어 수의 영향
- 목표: 서로 다른 트랜스포머 레이어 수가 CSLR 성능에 미치는 영향을 조사.
- 결과:
- 레이어 수가 증가할수록 네트워크가 더 추상적인 표현을 학습할 수 있어 성능이 처음에는 향상됨.
- 그러나 레이어 수가 많아지면 네트워크가 학습 데이터에 과적합(overfitting)하기 시작하여 성능이 저하됨.
- 결론:
- 최적의 성능을 위해 세 개의 레이어로 구성된 수어 트랜스포머를 사용.
5.4 Sign2Text and Sign2(Gloss+Text)
인식과 번역 작업을 하나의 모델로 통합
- 인식과 번역의 공동 학습:
- 인식과 번역을 동일한 가중치로 공동 학습하면, 번역 성능은 향상되지만 인식 성능은 전용 네트워크와 비교할 때 저하되었습니다. 이는 CTC 손실과 단어 수준 교차 엔트로피 손실의 스케일 차이 때문이라고 추정됩니다.
- 인식 손실 가중치를 증가시키면 인식 및 번역 성능이 모두 개선되었으며, 이는 관련 작업 간의 학습 공유의 가치를 나타냅니다.
- 이전 방법과의 비교:
- Sign Language Transformers는 이전에 발표된 방법들보다 인식 및 번역 성능에서 모두 우수한 성과를 보였습니다. Sign2Gloss와 Sign2(Gloss+Text) 설정 모두에서 테스트 세트에서 [39]보다 2% 낮은 WER을 기록했습니다.
- 특히, 우리의 Sign2Text와 Sign2(Gloss+Text) 네트워크는 이전의 최신 번역 결과를 두 배로 향상시켰습니다 (BLEU-4 점수 각각 9.58에서 20.17, 21.32로 증가).
- 우리의 최고 성능 번역 모델인 Sign2(Gloss+Text)는 Camgoz et al.의 텍스트-투-텍스트 기반 Gloss2Text 번역 성능을 능가했습니다 (BLEU-4 점수 19.26 대 21.32). 이는 더 정교한 네트워크 아키텍처가 주어지면, 제한된 글로스 표현을 통해 텍스트-투-텍스트 번역을 수행하는 것보다 비디오 표현에서 직접 번역하는 것이 더 나은 성능을 제공할 수 있음을 지원합니다.
6. Qualitative Results
전반적으로 번역의 품질은 좋으며, 정확한 단어 선택이 다를지라도 동일한 정보를 전달.
번역이 어려운 부분은 장소와 같은 고유명사인데, 이는 학습 데이터에서 제한된 문맥에서만 발생하기 때문.
특정 숫자도 구분할 문법적 문맥이 부족하여 도전 과제로 작용.
7. Conclusion and Future Work
8. Acknowledgements